好久沒有分享 SQL 題目讓大家玩了,最近剛好遇到兩個問題 排列組合 和 階層目錄,有興趣的大大可以挑戰看看。
原始資料 甲乙丙丁戊,請展開原始資料的所有組合,並需符合下列兩個條件。
甲乙 和 乙甲 算是同一個組合。甲乙 和 乙甲 需先展開 甲乙。結果不必排序,列出所有組合即可。
結果如下:
乙
乙丁
乙丁戊
乙丙
乙丙丁
乙丙丁戊
乙丙戊
乙戊
丁
丁戊
丙
丙丁
丙丁戊
丙戊
戊
甲
甲乙
甲乙丁
甲乙丁戊
甲乙丙
甲乙丙丁
甲乙丙丁戊
甲乙丙戊
甲乙戊
甲丁
甲丁戊
甲丙
甲丙丁
甲丙丁戊
甲丙戊
甲戊
DECLARE @Data TABLE
(
Id INT,
Txt NVARCHAR(10)
)
INSERT INTO @Data VALUES
(1,N'甲'),
(2,N'乙'),
(3,N'丙'),
(4,N'丁'),
(5,N'戊')
原始資料是具有階層性的目錄,結構如下:
DECLARE @Data TABLE
(
Id INT,
PatentId INT,
Txt NVARCHAR(1000)
)
原始資料如下:
最上層目錄的 PatentId 為 0。
Id PatentId Txt
----|----------|----------
1 | 0 | 1
2 | 0 | 2
3 | 1 | 1-1
4 | 1 | 1-2
5 | 2 | 2-1
6 | 3 | 1-1-1
現在需要用 --> 串出該目錄到 根目錄 的所有階層,結果如下:
Id PatentId Txt R
----|----------|----------|-----------------------
1 | 0 | 1 1
2 | 0 | 2 2
3 | 1 | 1-1 1 --> 1-1
4 | 1 | 1-2 1 --> 1-2
5 | 2 | 2-1 2 --> 2-1
6 | 3 | 1-1-1 1 --> 1-1 --> 1-1-1
DECLARE @Data TABLE
(
Id INT,
PatentId INT,
Txt NVARCHAR(1000)
)
INSERT INTO @Data VALUES
(1, 0, '1'),
(2, 0, '2'),
(3, 1, '1-1'),
(4, 1, '1-2'),
(5, 2, '2-1'),
(6, 3, '1-1-1')
DECLARE @Data TABLE
(
Id INT,
Txt NVARCHAR(10)
)
INSERT INTO @Data VALUES
(1,N'甲'),
(2,N'乙'),
(3,N'丙'),
(4,N'丁'),
(5,N'戊')
;WITH DLOOP (Id, Txt, R) AS
(
SELECT Id, Txt, Txt AS R FROM @Data
UNION ALL
SELECT B.Id,
B.Txt,
CAST (A.R+B.Txt AS NVARCHAR(10)) AS R
FROM DLOOP AS A
INNER JOIN @Data AS B ON B.Id>A.Id
)
SELECT R FROM DLOOP
ORDER BY R
DECLARE @Data TABLE
(
Id INT,
PatentId INT,
Txt NVARCHAR(1000)
)
INSERT INTO @Data VALUES
(1, 0, '1'),
(2, 0, '2'),
(3, 1, '1-1'),
(4, 1, '1-2'),
(5, 2, '2-1'),
(6, 3, '1-1-1')
;WITH DLOOP AS
(
SELECT Id, PatentId, Txt,
Txt AS R,
PatentId AS PrevId,
1 AS Dp
FROM @Data
UNION ALL
SELECT A.Id, A.PatentId, A.Txt,
CAST(B.Txt + ' --> ' + A.R AS NVARCHAR(1000)) AS R,
B.PatentId AS PrevId,
A.Dp + 1 AS Dp
FROM DLOOP AS A
INNER JOIN @Data AS B ON B.Id=A.PrevId
), DResult AS
(
SELECT Id, PatentId, Txt, R
FROM
(
SELECT *, ROW_NUMBER() OVER(PARTITION BY Id ORDER BY Dp DESC) AS G
FROM DLOOP
) AS A
WHERE G=1
)
SELECT * FROM DResult
這兩題都用到了 SQL 的 CTE 遞迴,這邊稍微簡單介紹一下。
CTE 遞迴結構
;WITH Recursive
(
--初始資料
SELECT * FROM XXX
UNION ALL
--遞迴查詢
SELECT * FROM Recursive
INNER JOIN YYY
)
遞迴結構分為兩個部分
上半部為初始資料的查詢
下半部為遞迴查詢,中間透過 UNION ALL 連接
程式運行時會先執行初始查詢的部分,這個部分只會進行一次
接著透過這些資料進行遞迴查詢
每次遞迴會將上一次下半部的查詢,當成下一次 CTE 的結果
而當下半部 查詢為空 時結束遞迴
這時會將之前每次遞迴的結果 UNION ALL 並回傳 (包含第一次上半部的結果)
執行過程蠻抽象的,不知道這樣表達,大家懂不懂

第一題是個排列組合問題,觀察結果後可以發現
每個項目的結果都是順向的,例如不可能出現 乙甲
因此我以 甲乙丙丁戊 為基礎
每次遞迴時將每個項目 JOIN 小於自己編號的所有項目
最後在將所有結果加在一起就是答案
甲的遞迴
第一次遞迴 第二次遞迴 第三次遞迴 第四次遞迴
-----------|-----------|-----------|-----------
甲乙 甲乙丙 甲乙丙丁 甲乙丙丁戊
甲丙 甲乙丁 甲乙丙戊
甲丁 甲乙戊 甲乙丁戊
甲戊 甲丙丁 甲丙丁戊
甲丙戊
甲丁戊
乙的遞迴
第一次遞迴 第二次遞迴 第三次遞迴
-----------|-----------|-----------
乙丙 乙丙丁 乙丙丁戊
乙丁 乙丙戊
乙戊 乙丁戊
程式說明
;WITH DLOOP (Id, Txt, R) AS
(
-- 初始化資料 甲乙丙丁戊
SELECT Id, Txt, Txt AS R FROM @Data
UNION ALL
SELECT B.Id, -- 每次回傳最後一位的Id
B.Txt, -- 每次回傳最後一位的Txt (其實不必這個欄位)
-- R為結果
-- A.R (上一次遞迴的結果) + B.Txt (這次 Join 的項目)
CAST (A.R+B.Txt AS NVARCHAR(10)) AS R
FROM DLOOP AS A
-- Join 編號小於自己的項目
INNER JOIN @Data AS B ON B.Id>A.Id
)
第二題如各位大大說的,是個標準的遞迴題
邏輯很單純每次透過 PatentId 找到上一層的目錄
不過有一點要注意,因為在遞迴過程會產生一些中間資料
因此最後要將這些資料過濾掉
例如以 1-1-1 這個目錄來看
第一次遞迴 第二次遞迴 第三次遞迴
-----------|---------------|---------------------
1-1-1 1-1 --> 1-1-1 1 --> 1-1 --> 1-1-1
最後結果會產生三筆資料,但其實我們只要最後一筆
1-1-1
1-1 --> 1-1-1
1 --> 1-1 --> 1-1-1 <-只需要這筆資料
因此在遞迴中我新增了一個 Dp 欄位,紀錄了目錄的層數,最後就可以利用 Dp 找出最長的那筆資料。
程式說明
;WITH DLOOP AS
(
-- 原始目錄
SELECT Id, PatentId, Txt,
Txt AS R,
PatentId AS PrevId,
1 AS Dp -- 設定第一層 Dp 為 1
FROM @Data
UNION ALL
SELECT A.Id, A.PatentId, A.Txt, -- 原始目錄的欄位
-- R為結果
-- B.Txt (為這次找到的上層目錄) + A.R (上一次遞迴的結果)
CAST(B.Txt + ' --> ' + A.R AS NVARCHAR(1000)) AS R,
-- PrevId 提供下一次遞迴要去 Join 的 PatentId
B.PatentId AS PrevId,
-- 目錄層數,最後用來找出最長的那個結果
A.Dp + 1 AS Dp
FROM DLOOP AS A
-- 利用 PatentId 找出上層目錄
INNER JOIN @Data AS B ON B.Id=A.PrevId
), DResult AS
(
SELECT Id, PatentId, Txt, R
FROM
(
-- 利用原始目錄 Id 進行分組,並以 Dp 排序
SELECT *, ROW_NUMBER() OVER(PARTITION BY Id ORDER BY Dp DESC) AS G
FROM DLOOP
) AS A
WHERE G=1 -- 找出最多層的那筆資料
)
解答拖了好多天,今天才有空發文,不知道大家有沒有玩的愉快。

我用暴力解法,目前想不到用遞迴解決,另外要做成動態的可以改成拼接sql + exec
--查詢
with cte as (
-- 1.1 先要藉由row_number()定義出甲跟乙誰最小得出RANK欄位
select *,row_number() over (
order by (
case val when N'甲' then 1
when N'乙' then 2
when N'丙' then 3
when N'丁' then 4
when N'戊' then 5
else val end
)
) rnk
from T
)
,CTE2 as (
--1.2 藉由CrossJoin + 前者RNAK小於後表RANK欄位得出"結果需由小的順位開始展開"需求,也順便排除同一個組合。
select T1.Val as result
from CTE T1
union all
select T1.Val+T2.Val as result
from CTE T1,CTE T2
where T2.rnk > T1.rnk
union all
select T1.Val+T2.Val+T3.Val as result
from CTE T1,CTE T2,CTE T3
where T2.rnk > T1.rnk and T3.rnk > T2.rnk
union all
select T1.Val+T2.Val+T3.Val+T4.Val as result
from CTE T1,CTE T2,CTE T3,CTE T4
where T2.rnk > T1.rnk and T3.rnk > T2.rnk and T4.rnk > T3.rnk
union all
select T1.Val+T2.Val+T3.Val+T4.Val+T5.Val as result
from CTE T1,CTE T2,CTE T3,CTE T4,CTE T5
where T2.rnk > T1.rnk and T3.rnk > T2.rnk and T4.rnk > T3.rnk and T5.rnk > T4.rnk
)
select * from CTE2
order by substring(result,1,1) desc,len(result) asc /*單純優化結果展示*/
結果:
result
甲
甲乙
甲丙
甲丁
甲戊
甲乙丙
甲乙丁
甲乙戊
甲丙丁
甲丙戊
甲丁戊
甲乙丙丁
甲乙丙戊
甲乙丁戊
甲丙丁戊
甲乙丙丁戊
戊
乙
乙丙
乙丁
乙戊
乙丙丁
乙丙戊
乙丁戊
乙丙丁戊
丙
丙丁
丙戊
丙丁戊
丁
丁戊
這一題可以使用標準遞迴解決
--測試資料
if(OBJECT_ID('#tempdb.#T') is not null) Drop table #T;
CREATE TABLE #T ([Id] int, [PatentId] int, [Txt] varchar(6));
INSERT INTO #T ([Id], [PatentId], [Txt])
VALUES (1, 0, '1'),(2, 0, '2'),(3, 1, '1-1'),(4, 1, '1-2'),(5, 2, '2-1'),(6, 3, '1-1-1');
--查詢
with CTE as (
select T1.ID,T1.Patentid,T1.Txt,convert(nvarchar(200),T1.Txt) as R
from #T T1
where patentid = 0
union all
select
T1.ID,T1.Patentid,T1.Txt,convert(nvarchar(200),T2.Txt + ' --> ' + T1.Txt ) as R
from #T T1
join CTE T2 on T1.patentid = T2.id
)
select * from cte
order by ID
結果
| ID | Patentid | Txt | R |
|---|---|---|---|
| 1 | 0 | 1 | 1 |
| 2 | 0 | 2 | 2 |
| 3 | 1 | 1-1 | 1 --> 1-1 |
| 4 | 1 | 1-2 | 1 --> 1-2 |
| 5 | 2 | 2-1 | 2 --> 2-1 |
| 6 | 3 | 1-1-1 | 1-1 --> 1-1-1 |
第6階 1-1-1
要往回找到 1-1 和 1
R = 1 --> 1-1 --> 1-1-1
大大排列組合的思路和我很像
每次 join 都只取 rnk 大於自己的項目
CREATE OR REPLACE FUNCTION f_combos(_arr anyarray)
RETURNS TABLE (combo anyarray) LANGUAGE plpgsql AS
$BODY$
BEGIN
IF array_upper(_arr, 1) IS NULL THEN
combo := _arr; RETURN NEXT; RETURN;
END IF;
CASE array_upper(_arr, 1)
-- WHEN 0 THEN -- does not exist
WHEN 1 THEN
RETURN QUERY VALUES ('{}'), (_arr);
WHEN 2 THEN
RETURN QUERY VALUES ('{}'), (_arr[1:1]), (_arr), (_arr[2:2]);
ELSE
RETURN QUERY
WITH x AS (
SELECT f.combo FROM f_combos(_arr[1:array_upper(_arr, 1)-1]) f
)
SELECT x.combo FROM x
UNION ALL
SELECT x.combo || _arr[array_upper(_arr, 1)] FROM x;
END CASE;
END
$BODY$;
--
SELECT * FROM f_combos('{1,2,3,4,5}'::int[]) ORDER BY 1;
+-------------+
| combo |
+-------------+
| {} |
| {1} |
| {1,2} |
| {1,2,3} |
| {1,2,3,4} |
| {1,2,3,4,5} |
| {1,2,3,5} |
| {1,2,4} |
| {1,2,4,5} |
| {1,2,5} |
| {1,3} |
| {1,3,4} |
| {1,3,4,5} |
| {1,3,5} |
| {1,4} |
| {1,4,5} |
| {1,5} |
| {2} |
| {2,3} |
| {2,3,4} |
| {2,3,4,5} |
| {2,3,5} |
| {2,4} |
| {2,4,5} |
| {2,5} |
| {3} |
| {3,4} |
| {3,4,5} |
| {3,5} |
| {4} |
| {4,5} |
| {5} |
+-------------+
(32 rows)
Time: 0.543 ms
好強 !
我記得plpgsql...在裡面有寫CASE WHEN的狀況下,好像(非常神奇地)可以不用控制項,WHEN 2那邊感覺多寫了,ELSE已經寫得很漂亮。我測一下晚點貼上來。
大大的遞迴用的真巧妙
CASE1 和 CASE2 定義了遞迴的最小單位
之後的每一層就按照回傳加入新項目
最後 UNION ALL 的地方看了好久才明白
以 {1,2,3} 為例
SELECT x.combo FROM x
-- 結果為
1
1,2
2
UNION ALL
SELECT x.combo || _arr[array_upper(_arr, 1)] FROM x;
-- 結果為
1,3
1,2,3
2,3
3
如果再多一層 {1,2,3,4} 就是
SELECT x.combo FROM x
-- 結果為
1
1,2
2
1,3
1,2,3
2,3
3
UNION ALL
SELECT x.combo || _arr[array_upper(_arr, 1)] FROM x;
-- 結果為
1,4
1,2,4
2,4
1,3,4
1,2,3,4
2,3,4
3,4
4
上半部為上一層的回傳,下半部為上一層加新項目的結果,UNION ALL 後就是答案,這裡很漂亮。
(刪除)
DROP FUNCTION IF EXISTS fun1(r anyarray);
CREATE OR REPLACE FUNCTION fun1(r anyarray)
RETURNS TABLE(category anyarray) LANGUAGE plpgsql AS
$BODY$
BEGIN
CASE array_upper(r,1)
WHEN 1 THEN RETURN QUERY VALUES ('{}'),(r);
ELSE RETURN QUERY
SELECT b.category
FROM(SELECT a.category FROM fun1(r[1:(array_upper(r,1)-1)])a)b
UNION ALL
SELECT b.category || r[array_upper(r,1)]
FROM(SELECT a.category FROM fun1(r[1:(array_upper(r,1)-1)])a)b;
END CASE;
END
$BODY$;
--測試結果
SELECT * FROM fun1('{甲,乙,丙,丁,戊}'::text[]);
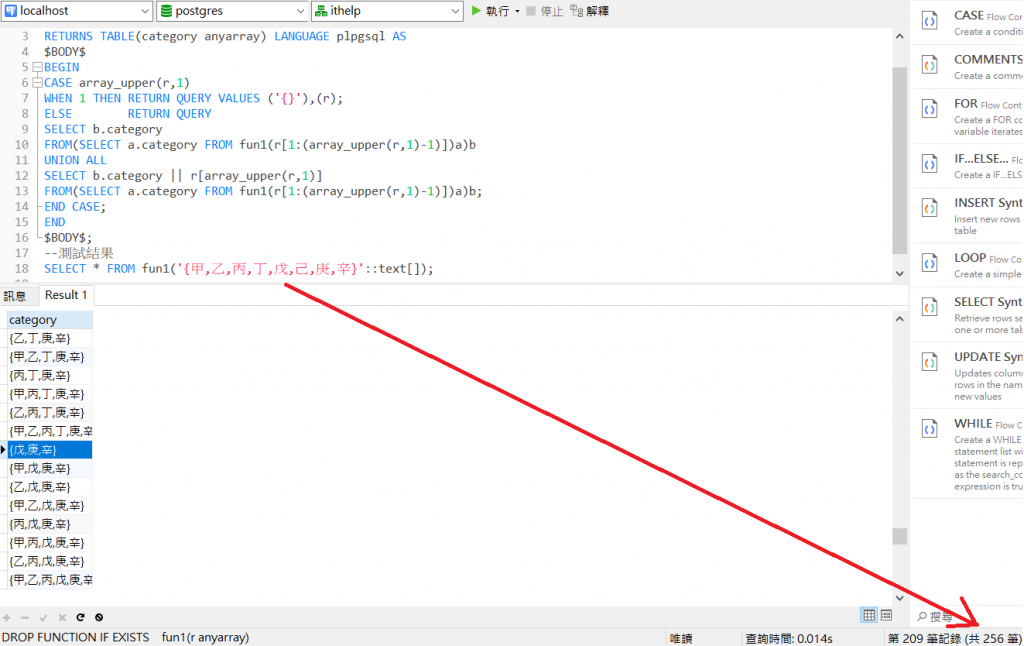
製作原理和一級屠豬士相同,只是拿掉了控制項、移除when 2 (ELSE有蓋到when2了)、還原x(這邊一級屠豬士寫得比較漂亮精簡,只是我個人沒這習慣)。
話說回來,雖說之前有經驗,知道這樣寫就跑得起來,但完全不懂為什麼可以不用寫控制項(while or IF&ENDIF or for迴圈),系統是怎麼判斷怎樣叫跑完、怎樣要繼續跑,我蠻好奇的,版上有沒有大師可以開導指教一下?
functional programming....
{} / NULL 遞迴傳遞回去
第三種寫法出現了!!! 也是使用 plpgsql,小弟沒有寫過所以對語法好陌生,臨時 Google 惡補了好多語法。
我嘗試回答大大最後的問題。
以 {甲,乙,丙} 為例
我畫了一張圖,應該會比較清楚
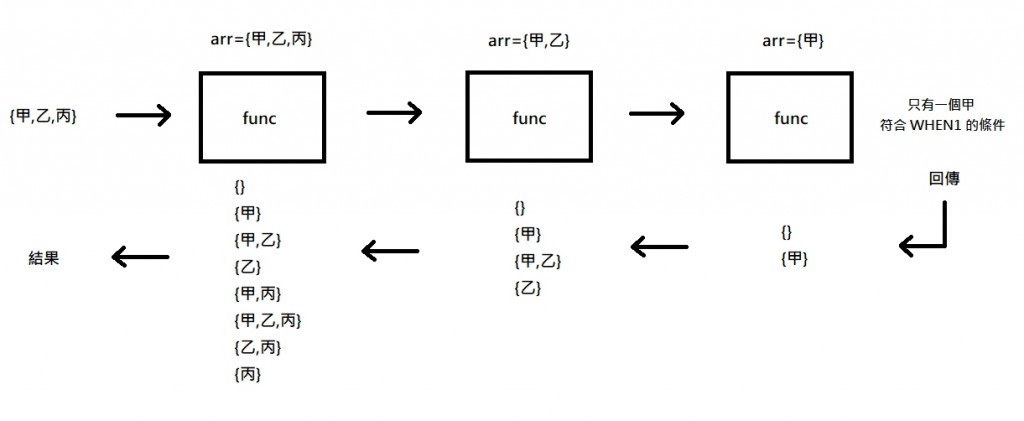
進入遞迴函數後,因為遇到 ELSE 所以會一直往下呼叫
直到最後一層遇到 WHEN 1,這時有了第一個回傳 {}和{甲}
接著回傳的過程結果會不斷疊加,直到第一層離開函數
這時的 RETRUN 就是結果
可以發現遞迴函數和 while 等迴圈不太一樣
是有深度的循環,函數一層一層的呼叫,再一層一層的回傳
直到 退出第一層函數 就是遞迴的結束
表達不太好,不知道您能不能理解
 小碼農米爾
小碼農米爾
